很多SEO新手都会有一个疑问:
Google到底是怎么发现网站的?
为什么:
有的网站刚发布几小时就被收录,
而有的网站:
几个月都没有流量?
其实答案很简单:
因为Google背后有一个巨大的网页发现系统:
Googlebot。
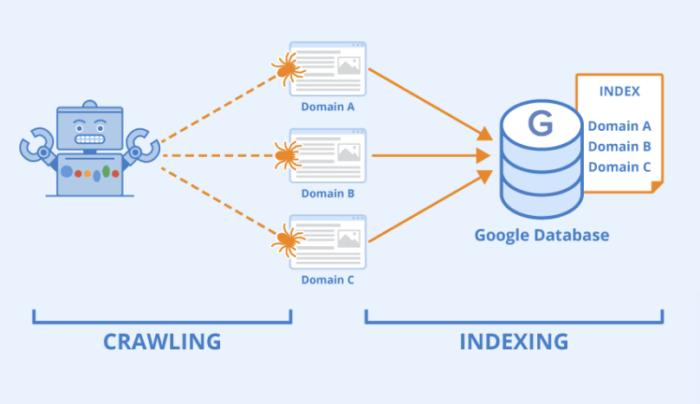
Googlebot是Google官方的网络爬虫。
它每天都在互联网中:
发现网页、
抓取内容、
分析页面、
更新索引。
SEO的第一步,
其实并不是排名,
而是:
让Google发现你的网站。
文章目录
什么是Googlebot?
Googlebot:
是Google官方的网页爬虫(Web Crawler)。
它也被称为:
- Spider(蜘蛛)
- Crawler(爬虫)
- Bot(机器人)
Google官方也提供了关于Googlebot的详细说明:
简单来说:
Googlebot就像一个自动浏览网页的机器人。
它会不断访问互联网中的网页,
并把网页内容带回Google数据库。
Googlebot每天都在做什么?
Googlebot每天主要做四件事:
1、发现新网页
Google会不断寻找新的:
- 网站
- 页面
- URL
这些页面可能来自:
- 外链
- Sitemap
- 网站内链
- 用户提交
2、抓取网页内容
当Googlebot进入网页后,
它会读取:
- HTML
- CSS
- JavaScript
- 图片
- 页面链接
这一步叫:
Crawling(抓取)。
Google官方对Google爬虫类型也有详细说明:
3、分析页面内容
Google会尝试理解:
这个页面到底在讲什么。
例如:
它会分析:
- Title标题
- H1/H2结构
- 正文内容
- 图片Alt
- 内链结构
- Schema结构化数据
Google现在已经不仅仅依赖关键词,
而是更重视:
语义理解。
4、决定是否收录
Google抓取页面后,
不会立刻收录。
它会继续判断:
这个页面是否值得进入Google索引库。
如果页面:
- 内容重复
- 质量太低
- 没有搜索价值
那么:
即使被抓取,
也可能不会收录。
Google是如何发现网站的?
Google发现网站主要有4种方式。
1、通过外链发现网站(最重要)
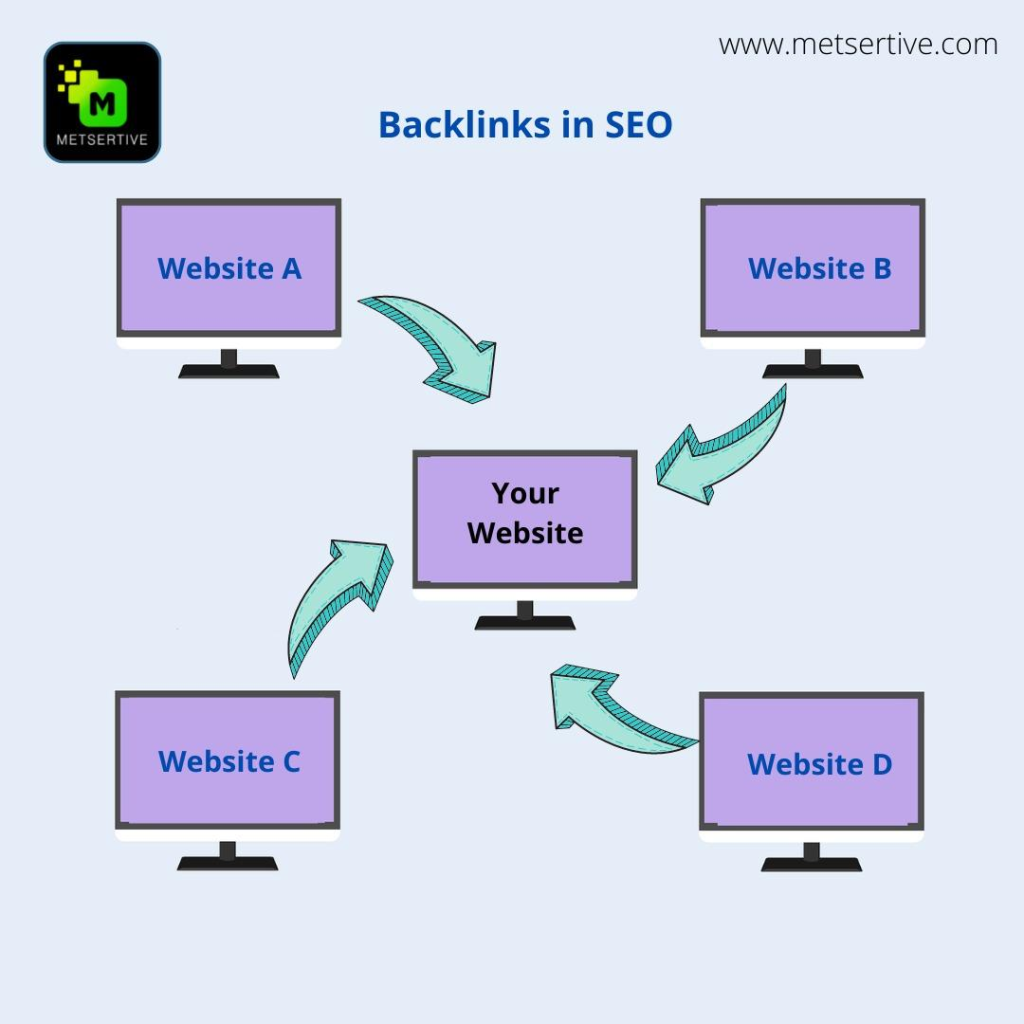
这是Google最核心的网页发现方式。
例如:
A网站链接到你的网站:
A网站 → 你的页面
Googlebot会顺着这个链接继续抓取。
这也是为什么:
外链不仅影响排名,
还影响:
网页发现效率。
很多新网站:
第一批Google爬虫,
其实就是通过外链进入网站的。
2、通过Sitemap发现页面
Sitemap:
本质上是网站地图。
它会主动告诉Google:
“我的网站有哪些页面”。
例如:https://www.dreamixo.com/sitemap.xml
Google官方也建议网站提交Sitemap:
对于新网站来说:
Sitemap非常重要。
因为:
新网站:
- 权重低
- 内链少
- 页面少
Google可能很难主动发现页面。
3、通过网站内链抓取
Googlebot会顺着网站里的链接继续抓取。
例如:
首页 → 分类页 → 文章页
如果网站结构清晰,
Google会更容易理解网站。
这也是为什么:
SEO非常强调:
内链结构。
很多页面不收录,
其实并不是内容问题,
而是:
Google根本找不到页面。
4、通过Google Search Console主动提交
你也可以在:
Google Search Console
主动提交页面URL。
Google通常会优先尝试抓取。
这对于:
- 新页面
- 新网站
- 更新后的页面
非常有帮助。
什么是抓取预算(Crawl Budget)?
抓取预算:
是技术SEO中的重要概念。
Google不会无限抓取一个网站。
每个网站:
都有自己的抓取预算。
简单理解:
Google愿意花多少资源抓取你的网站。
影响抓取预算的因素包括:
- 网站权重
- 更新频率
- 页面数量
- 服务器稳定性
- 网站速度
- 内容质量
高质量网站:
通常抓取频率更高。
例如:
新闻网站。
因为:
它们内容更新非常频繁。
为什么新网站抓取很慢?
很多SEO新手都会发现:
新网站:
即使发布文章,
Google也很久不抓取。
原因通常包括:
- 没有外链
- 网站权重低
- 内容太少
- 更新频率低
- Google缺乏信任
因此:
新网站前期:
最重要的是:
持续更新高质量内容。
Googlebot会抓取JavaScript网站吗?
会。
Google现在已经支持JavaScript渲染。
但:
JS网站:
抓取成本更高。
因此:
很多JS网站:
会出现:
- 收录慢
- 抓取延迟
- 内容识别不完整
所以SEO通常更推荐:
- SSR(服务端渲染)
- 静态渲染
- WordPress
因为这些方案:
更利于Google抓取。
Google最讨厌什么网站?
Googlebot最不喜欢以下几类网站:
1、打不开的网站
例如:
- 服务器崩溃
- 页面超时
- 500错误
2、低质量内容网站
例如:
- AI拼接内容
- 采集站
- 伪原创内容
3、大量404页面
死链太多,
会浪费Google抓取资源。
4、无限重复URL
例如:
参数页面无限生成。
Google会认为:
网站结构混乱。
为什么页面抓取了但没收录?
很多新手误以为:
“抓取 = 收录”。
实际上:
完全不是。
Google抓取后,
还会继续评估页面质量。
常见不收录原因包括:
- 内容质量低
- 页面内容重复
- 搜索需求不足
- 网站权重太低
- 页面价值不高
这也是为什么:
SEO不仅仅是让Google抓取页面,
更重要的是:
让Google认为页面值得收录。
如何让Googlebot更喜欢你的网站?
核心有5点:
1、持续更新内容
Google更喜欢活跃网站。
2、优化网站速度
网站越快,
Google抓取效率越高。
3、做好内链结构
帮助Google发现更多页面。
4、提交Sitemap
主动告诉Google网站结构。
5、提高内容质量
真正帮助用户。
这是最核心的SEO原则。
总结
Googlebot本质上:
是Google的信息收集机器人。
它负责:
- 发现网页
- 抓取网页
- 理解内容
- 更新索引
SEO很多时候,
本质上就是:
帮助Google更容易理解你的网站。
如果:
Google发现不了页面,
后面的排名:
几乎都不存在。
因此:
SEO第一步:
永远是:
让Google发现页面、
顺利抓取页面、
正确理解页面。
推荐阅读